A recent conversation with a friend in the robotics industry naturally led to a discussion of how the industry as a whole can build more generalizable robotic systems: systems that can perform well in novel tasks with little new data, systems that are robust to task perturbations, and systems that can adapt to different robot morphologies. We discussed prospects for leveraging large datasets of heterogeneous robotics data and the lessons we can take from the astonishing success of LLMs/other foundation models. This post explores that topic further.
Below I summarize some of the areas of intense general robotics research over the last few years. It focuses on the attempts to leverage LLMs/VLMs and related techniques for robotics and what techniques might prove fruitful for extracting the most value out of large robotics datasets. These techniques are being applied all across the robotics field to varying success. Considering my active work on driverless vehicles, I avoid analyzing related advances in autonomous driving. Instead, I focus this review mostly on grasping and manipulation robots, as that is an area of particular research emphasis. I think the lessons learned in this robotics sub-domain extend to most other areas of robotics.
As a preliminary historical note, the idea of using data from other robots or models trained on non-robotics data to build better robots is still a novel one. The hand-engineered components in conventional robotics systems (pre-deep learning) struggled to leverage robot data at all except to scrutinize directly for debugging purposes. To be clear, model based approaches can still produce powerful results, including the notable robot parkour exhibited by Boston Dynamics robots. However, this post assumes a more modern architecture that includes data driven components that are architected to enable learning from data, whether generated directly by the target platform or otherwise.
LLMs & foundation models in robotics research
Massively scaled LLMs (and multivision-language VLMs) have exploded onto the scene over the past few years, demonstrating astonishing capabilities in text and other modalities (images, video, 3D assets, etc.). The impressive ability of these models to extend to complex tasks is incredibly enticing for a robotics field where highly specialized task-specific robots are the norm. Robotics research efforts have explored numerous methods for leveraging these advances, ranging from directly incorporating existing LLMs in the loop, to attempting to replicate critical attributes of the LLM approach (mostly massive scale) with robotics data. Critical questions are still unanswered, including whether we will need to scale robot-specific datasets to the same size as LLMs to achieve similar levels of generalization, or whether we can use LLMs in the loop as a shortcut to extract the reasoning these models contain and apply it in an embodied application.
Using LLM to construct language-based robot plans
The first set of techniques leverages an LLM to map natural language instructions for a robot into a sequence of natural language instructions for the robot to follow, consistent with the low-level capabilities the robot provides. SayCan represents some of the earliest work on this approach. Given a set of affordances (robot capabilities), the LLM is used to translate high level language directives into low level actions for the robot based on likelihood of that action achieving the user’s specified request and the likelihood of the robot succeeding at that task (based on a value function). In SayCan, these low-level skills were composed of over 500 individual policies trained for specific tasks, each associated with navigating to or manipulating specific objects. The LLM in this system was constrained to a sequence of language and dependent on a complex set of lower-level policies to enable actual robot control, but the work shows the benefit of using the LLM’s higher level reasoning and planning capabilities.
Tokenizing robot perception and control
SayCan depended on a large library specialized of low-level policies the LLM could compose sequentially to solve tasks. This was necessary because robots don’t natively operate in a flexible representation like natural language - they ingest sensor data from a carefully engineered sensor suite and output carefully control signals designed for that specific robot. Several subsequent works have focused on adapting sensor data and control actions to essentially resemble language tokens, bridging this gap and allowing the LLM to control the robot directly.
Palm-E extended the original approach from SayCan by allowing continuous observations from the robot to be injected into the language model as language tokens and scaling up the language model. Encodings for robot observations were trained with robot tasks and adjacent tasks (like image captioning), enabling success on more complex tasks that often required multiple steps. The core idea here is to take sensor inputs and embed them in the same space as language tokens the model is designed to process.
RT-1 completed the puzzle by tokenizing both inputs (history of images and task descriptions) and tokenizing outputs (robot actions), creating a transformer-based architecture for robot control that can act on language-based task instructions. RT-2 extended this further by incorporating an LLM in the architecture to aid in generalization to new tasks. In that work, the entire LLM was co-fine-tuned with a dataset containing robotics data (requiring robot action token outputs) and adjacent tasks like image captioning. The goal of this hybrid fine tuning was to encourage the model to learn robot action outputs alongside other more general vision tasks, enabling exploitation of internet-scale datasets while specializing for robot applications. In this architecture, an image from the robot (passed through a vision transformer encoder) and a language prompt is fed into the model and model outputs are decoded from individual output tokens into robot actions. In RT-2, a discretized action space was used to form a “vocabulary” for the model to generate, with tokens representing changes in position, rotation, and gripper actuation.
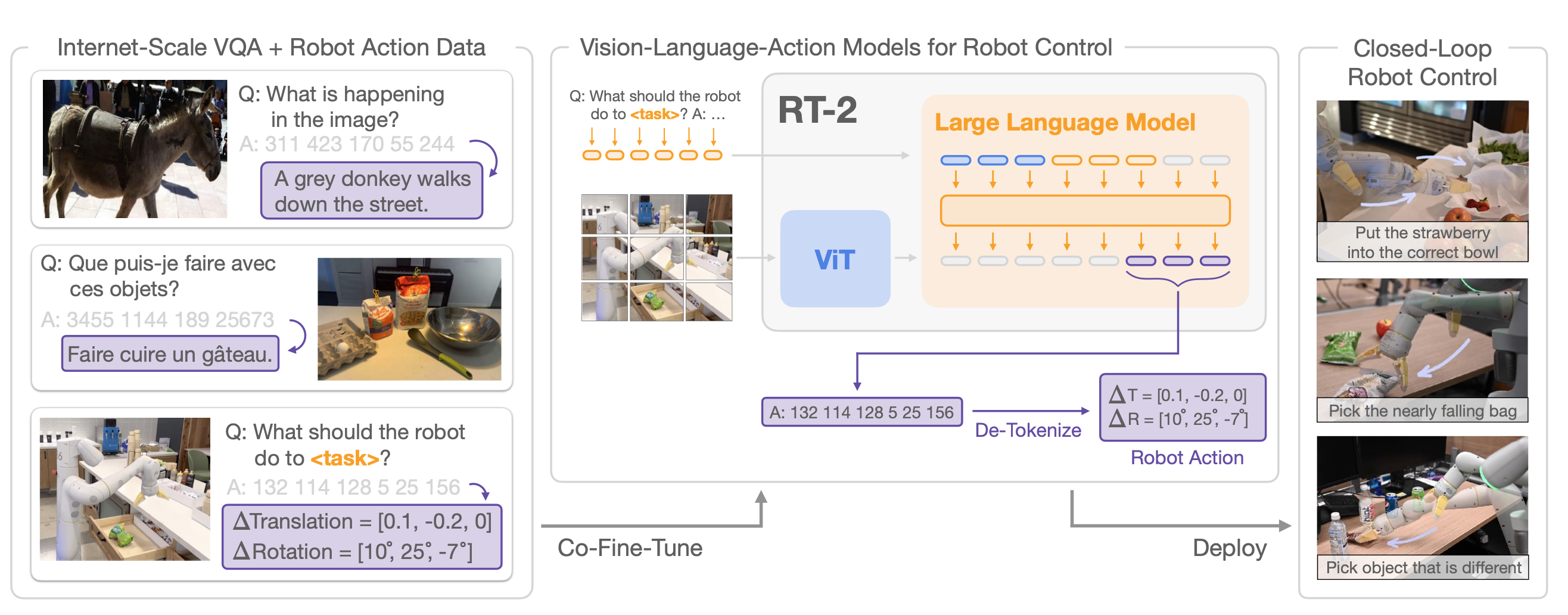
While RT-2 did show some ability to operate better on unseen objects compared to the RT-1 baseline, some limits were discovered. Specifically, using the 55B LLM showed essentially no improvement on performance compared to the 12B LLM on unseen tasks, suggesting scaling the LLM at the core of this architecture did not further increase generalization to new tasks.
Aggregating large-scale robotics dataset to learn robot foundation models
Using existing LLMs/VLMs as a backbone is appealing because these models already have rich capabilities due to the internet-scale data composing their training datasets. However, massive LLMs/VLMs are often too large to be practical for fast inference on embodied robots. In RT-2, for example, the 12B model had to be run on dedicated cloud infrastructure, increasing system complexity and limiting the practical ability to leverage such models to low-level control. Further, the model’s language-oriented capabilities are excessive and not tuned for precise control tasks necessary in robotics. Using existing LLMs may not be the right approach, but the lesson that massive scale of model size and training data is crucial cannot be ignored.
In response, a new focus has been placed on assembling large, varied datasets specifically to learn foundation models for robotics. Recent academic efforts like Open-X now have robot datasets exceeding 1 million trajectories across 22 different robots. Other approaches use egocentric videos (first-person view) as a substitute for robotics data that is easier to capture. These datasets are still small relative to the internet-scale datasets of LLMs, but enough to start investigating whether the scaling benefits of LLMs are also applicable to robotics data.
Research using the Open-X dataset to learn generalist robot policies is producing compelling results. Applying prior methods-including RT-2 discussed above-on this larger dataset creates significantly improved policies (authors claim a 3x improvement in “emergent skills” on RT-2-X vs prior RT-2). Even more recent work called Octo learned a generalist policy from the Open-X dataset that not only outperformed prior methods, but demonstrated the ability to operate on several different robot embodiments. Performance on specific robots was greatly enhanced through a small amount of fine tuning, which is accommodated in the Octo architecture. The transformer architecture used by Octo employs a flexible tokenization scheme allowing robot-specific input observations (like proprioceptive sensor data) and customized control outputs. Out of the box, Octo is capable of controlling several different types of robots (although fine tuning is still necessary when the configuration changes significantly).
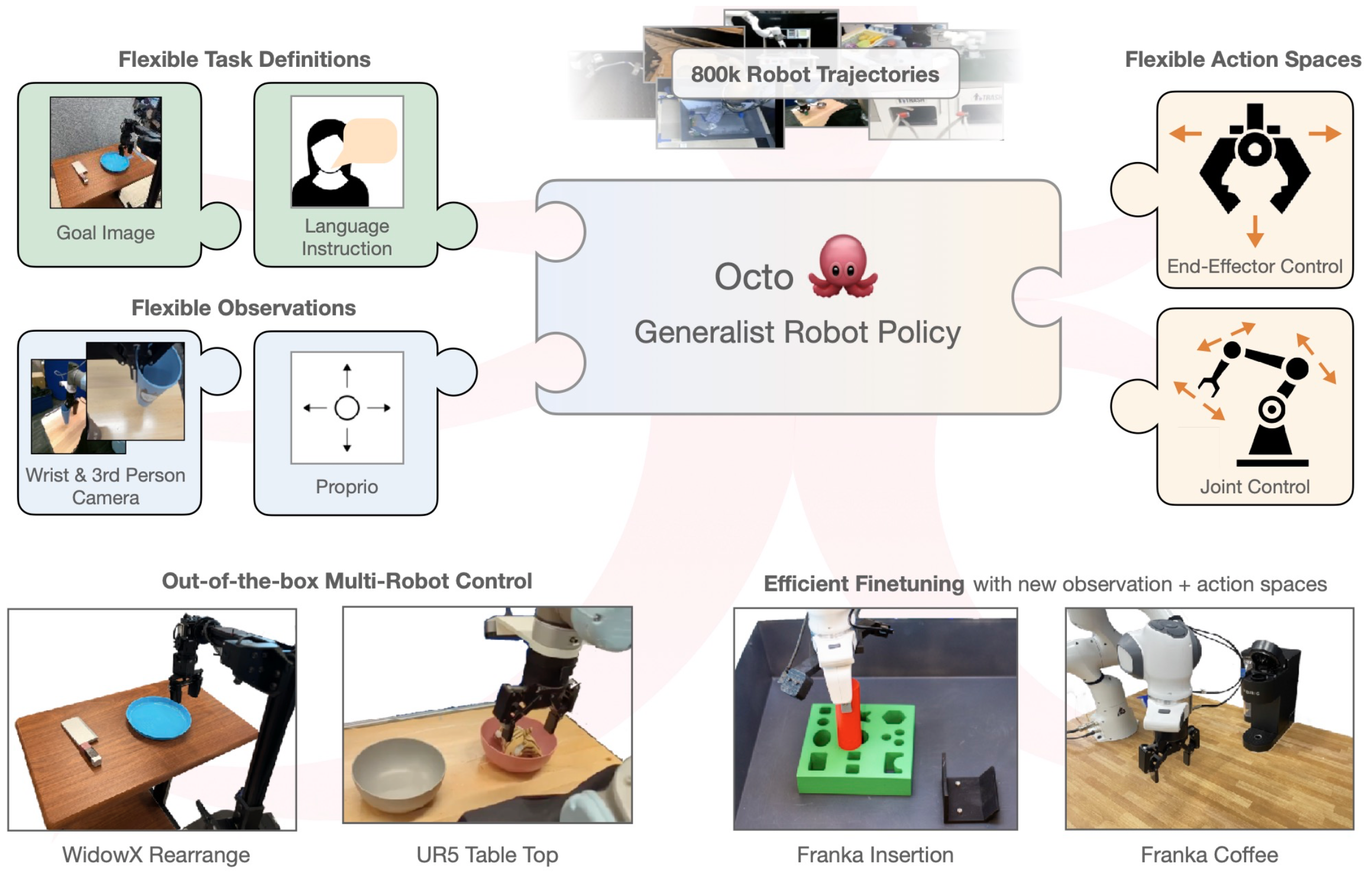
Despite the successes of Open-X, collecting high volume robotics data remains complex and relatively expensive. And although the available robotics datasets are growing, the scale of available data is still minuscule in comparison to the language and image datasets used to train large LLMs/VLMs. To address this gap, another line of work focuses on pre-training tasks representations for use in downstream robotics tasks in a way that can leverage large scale image and video data even if it wasn’t collected by robots.
Leveraging pre-trained representations specialized for robot applications
Early work in this area focuses on learning visual representations from first-person visual data and then leveraging these representations for robotics tasks. These methods used datasets that include general visual data (like ImageNet) and various datasets of first-person, task-oriented videos like Ego4D and 100 Days of Hands. Real-World Robot Learning with Masked Visual Pre-training (MVP) explored whether it was possible to learn useful representations from this composite dataset using a masked autoencoder, a self-supervised learning formulation similar to the approach used in LLM pre-training. The resulting vision encoder was then frozen and then combined with downstream control policies to benchmark performance, showing superiority over other visual encoders like CLIP.
R3M, also operating on Ego4D, leveraged task-oriented videos with language annotations and created a pre-training system that enforced video-language alignment. It then benchmarked these representations using imitation learning to train the policy, once again demonstrating superiority over more generic vision encoders. Voltron followed these and extended the approach into a broader framework. A key contribution was implementing a more complicated approach for integrating language, where the model is trained to balance conditioning on input language and attempting to generate natural language predictions associated with the input image. This effectively leverages the reconstruction approach of MVP combined with a language generation task that was shown to improve performance, particularly on higher level tasks.
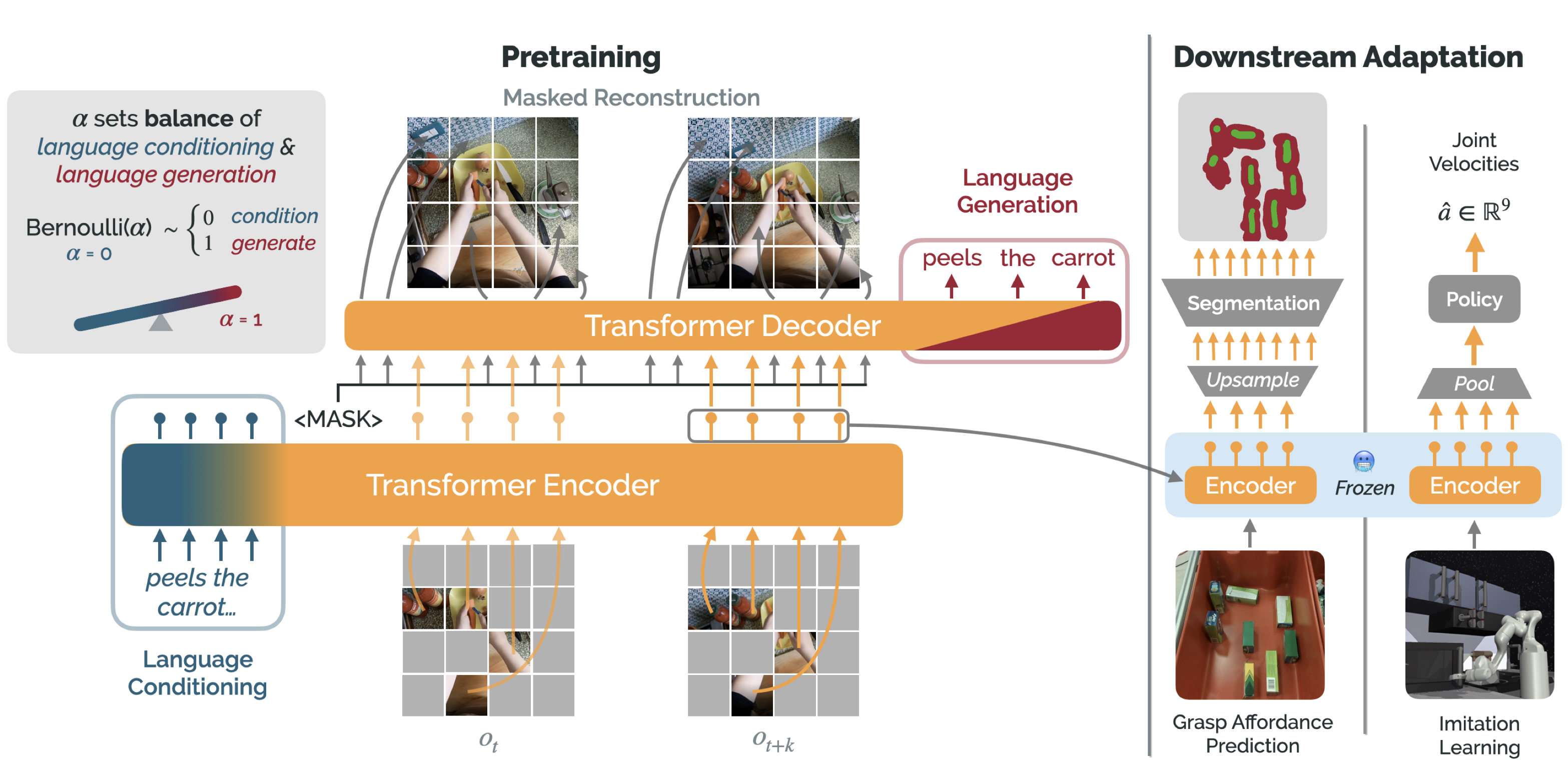
The Voltron architecture depicting combination of MAE and language generation training formulation
Work continues on the best formulation for pre-trained visual encoders for robotics. VC-1 contains a summary of progress and tradeoffs. It also presents the VC-1 pre-trained vision encoder trained from 4,000 hours of egocentric videos and additional data from ImageNet (totaling 5.6M images). The authors applied the VC-1 encoder to numerous tasks, using behavior cloning to train the policy. VC-1 outperforms CLIP on every benchmark, making it clear that the egocentric videos used to train VC-1 are useful for robot tasks. Also, the authors show that VC-1 outperforms prior pre-trained visual representations on most tasks, but that for many benchmarks, encoders leveraging more task specific data are still superior (see Sec 5.2).
With the powerful VC-1 robotics vision encoder available, LLaRP cleverly combines this with an off-the-shelf LLM. Like RT-1 and 2, LLaRP similarly focuses on tokenizing robot data to integrate with an LLM. For vision observations, this is done using a frozen VC-1 encoder. LLaRP bolts this on to an frozen LLM and also adds decoders to emit action tokens. These encoder/decoders are trained using RL to derive a policy for the robot. This architecture cleverly combines a state-of-the-art pre-trained vision encoder, an LLM trained on internet-scale data, and RL for fine tuning. Instead of dealing with the complexities of training the LLM (like RT-2’s coupled co-fine-tuning), LLaRP instead leverages the reasoning ability of the frozen LLM but includes additional modules to train with RL to discover good encoder/decoders to integrate the LLM with the robotics. The use of RL in this architecture brings about its own complexities and challenges, but it lays out one approach for achieving compelling results-at least in simulation - without needing any bespoke robotics data.
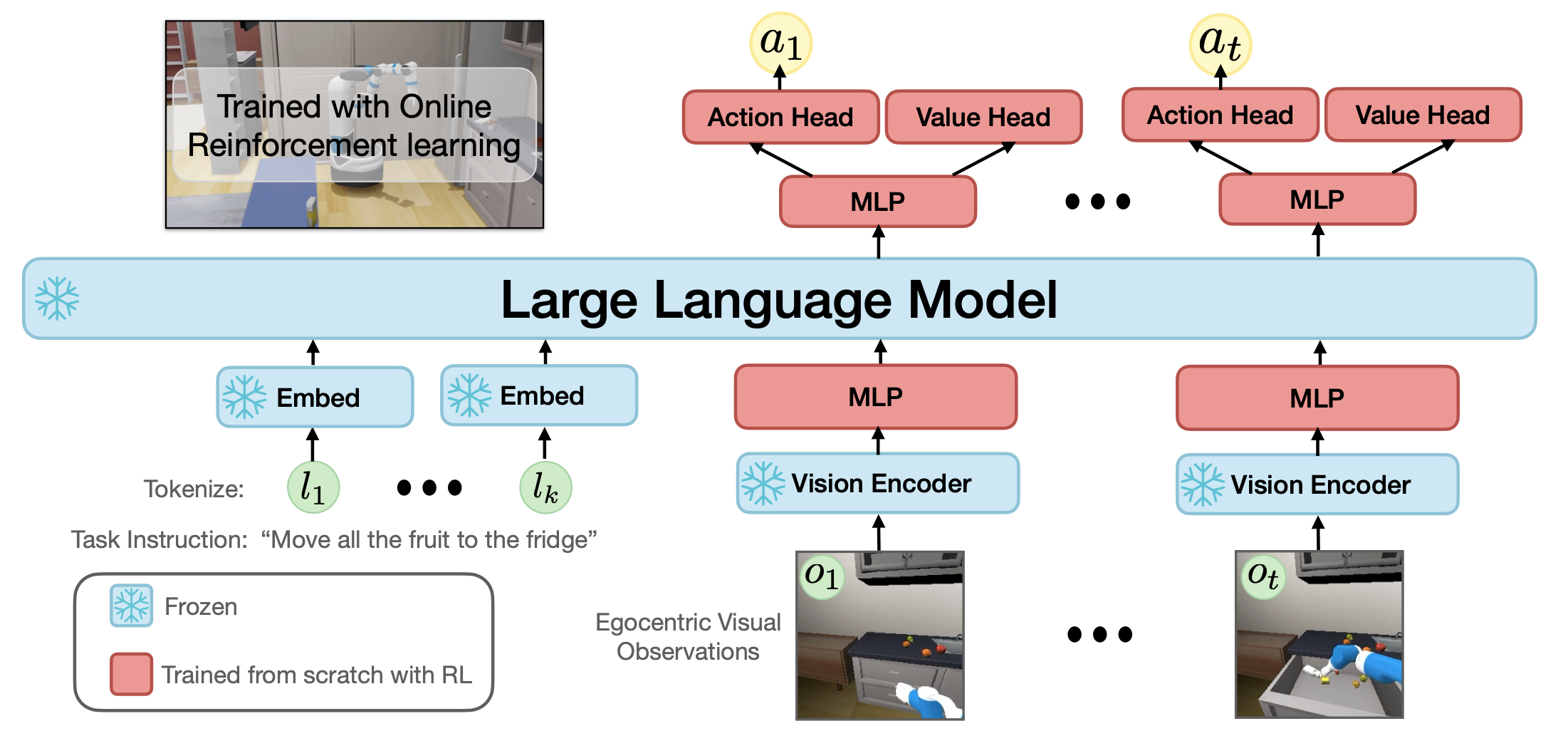
LLaRP architecture
Despite the success of VC-1 and similar large-scale robotics vision encoders leveraging ego-centric video data, it isn’t clear that ego-centric videos are directly transferable to robotics tasks. Ego-centric videos of humans completing tasks are a tempting source of data due to scalability and relative ease of collection, and foundation models like VC-1 shows this type of data can help learn powerful representations. In Diffusion Policy (discussed below), the authors found that pre-trained vision encoders (R3M in their case) perform better than ImageNet, but still worse than training end-to-end on task-specific data.
Similarly, Octo (the generalist policy discussed above) demonstrated that learning from Open-X robotics data and then fine-tuning for a particular robot and task still produces superior results compared to starting with pre-trained VC-1 representations. This is likely due to the robot demonstration data in Open-X simply being more suited to the ultimate application. However, the authors also note that Octo’s architectural flexibility is likely even more important, as it can accept proprioceptive sensory data that isn’t available in video-only approaches:
The results also underline Octo’s ability to accommodate new observations (force-torque inputs for “Berkeley Peg Insert”) and action spaces (joint position control for “Berkeley Pick-up”). This makes Octo applicable to a wide range of robot control problems that go beyond a single camera input and end-effector position control.
Pre-trained vision encoders for robotics certainly have value, but in many practical, real-world deployments, incorporating robot-specific data will still be useful for achieving the best possible performance.
Adjacent opportunities
Incorporating diffusion
Alongside LLMs, large-scale diffusion models are also gaining extreme notoriety due to the stunning results in generative modeling, particularly in images but also in audio and even in video. These models are trained on large datasets and learn to iteratively generate samples from the underlying distribution being modeled. This method has proven quite robust at generating high quality results, including operating in very high dimensional output spaces. Diffusion models have extended this success to formulations where the generation is conditioned on some other input like language or an image. As with LLMs, these massive breakthroughs haven’t been lost on the robotics community and the method has contributed to some interesting robotics results.
A common approach is to leverage a diffusion model to generate plans for the robot, conditioned on language and other sensory input, as a direct replacement for the tokenized transformer policies common in previously discussed work. Diffusion Policy explored this idea on a robot arm application, modeling the trajectory of the robot as the output target of the diffusion process, conditioned on language and sensory input information.
This work discovered several exciting properties of diffusion models for this purpose, including successful extension to high dimensional output spaces (trajectories for complex robots extending for long horizons), temporal action consistency, and the ability to express multi-modal options precisely (locking in to a plan when there are multiple valid trajectories to perform an action). Unlike the tokenized actions of RT-1, 2, and related work, the diffusion approach also allows the policy to operate in a continuous action space, likely reducing the need for any downstream trajectory optimization or smoothing for stable robot behavior. Octo did incorporate a diffusion output head, showing that translation from action tokens to a continuous, multimodal action space is possible.

Visualization of Diffusion Policy in action
Unfortunately, the iterative nature of the diffusion process does have negative implications for inference time. In the Diffusion Policy work, the core diffusion model can only be executed every 0.8s. This limitation may be suitable for some tasks, but many robotics tasks require much more rapid inference and re-planning.
Another application for diffusion models in robotics is to compensate for limitations in the variety or volume of training datasets using diffusion approaches to synthetically augment available data. In ROSIE, text-guided diffusion models were used to augment training data by selectively replacing elements of the scene with modified substitutes. The paper provides several examples where a relevant object in a successful training episode can be synthetically substituted with a different object via an internet-scale diffusion model, rendering multiple useful training examples to learn from. Because the authors use internet-scale diffusion models that generalize well, “[t]his amounts to a free lunch of novel tasks, distractors, semantically meaningful backgrounds, and more.”
Alternative task representations
Much of the work on pre-trained representations focus on learning useful representations of the state, including the desired task. For most of the prior methods and much of the recent research, the task is represented using language. Language has been shown to be quite powerful in aiding generalization, but it does have limitations. One limitation is simply on the data collection side. Collecting dense language annotations is expensive and challenging to scale. This constrains dataset size. Addressing this problem, GRIF uses a small amount of language annotations and a mutated CLIP model to align language instructions with transition from starting state to goal state (represented as two images). This opens the door to learning from unstructured data from high volume sources (like internet-scale video) by eliminating the reliance on dense language annotations for every example. Octo actually adopts this goal-conditioned approach, allowing tasks to be specified with language or a goal image.
Another issue with task specification via language is simple ambiguity and under-specification. Consider a language task like “place the apple on the counter.” For a task specified with language, there are potentially many end states that satisfy the task. The robot could gleefully position the apple right on the edge of the counter, far from where a human would think to position it for later use. Goal image conditioning has the opposite problem. If the robot gets an image of an apple on the counter as its goal, it might invest unnecessary time and energy into placing the apple in exactly the same spot at exactly the same orientation as the goal image. RT-Trajectory aims to resolve this issue by conditioning the policy on a coarse trajectory for completing the task.
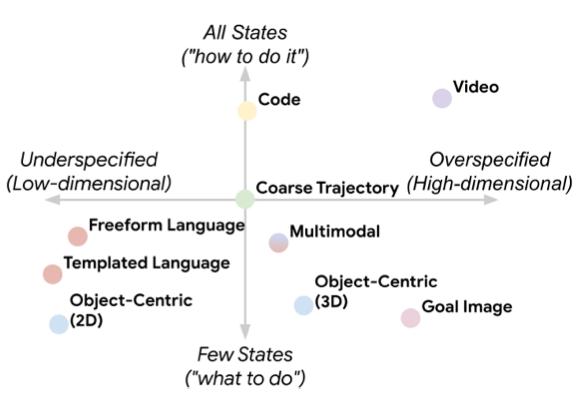
RT-Trajectory authors outline tradeoffs between different task representations.
In RT-Trajectory, these coarse trajectories are represented as 2D annotations applied over egocentric camera views from a robot arm. Interaction markers are noted with symbols, and gripper paths are depicted as lines tracing the path of the gripper, projected into the 2D camera view. Relative temporal motion is encoded with varying colors of the trajectory path. This representation allows hindsight trajectories from prior attempts to be collected at scale, both from the robot and from ego-centric videos of human demonstrations (via hand tracking). However, it also allows humans to quickly sketch a trajectory to specify a task. The authors even experiment with prompting an LLM to draw a trajectory with some success. This technique for task specification likely isn’t suitable for more general mobile robots, but does indicate some promising research directions in developing more flexible and express task representations.
Is scaled up robotics-specific data even necessary?
Despite the compelling results produced by using scaled up robotics datasets, it isn’t completely established that domain-specific datasets will be necessary. Recent work in OK Robot composed a full system used an “off the shelf” VLM (Owl-ViT, a detection-oriented modification to CLIP) along with a language-conditioned segmentation model (Lang-segment anything) to create a robot that can respond to language requests to manipulate and transport household items for the requester. While using robot-specific data is proving important for granular manipulation tasks, OK Robot shows there’s a decent chance the original approach from SayCan to “just integrate the internet-scale models” might be enough, at least in some applications. I should note that while OK Robot did provide impressive results, the system involves numerous heuristics and a very complicated combination of systems. The authors themselves note that having such a large collection of modules limits robustness, and the resulting complexity might push designers back toward domain-specific approaches.
Highly specialized expert demonstration data still shines
On the other side of the spectrum, recent work has shown that collecting large amounts of very high quality expert demonstrations on the exact same robotics platform is extremely useful for learning precise capabilities. Videos of Mobile ALOHA recently went viral due to the extraordinary capabilities the robot demonstrated, including cooking shrimp, loading the dishwasher, and moving a wine glass to clean up the spill underneath it. This work extended ACT which showed that collecting expert demonstrations via teleoperation enabled learning fine-grained control. The system used in Mobile ALOHA allowed a human operator to move with the manipulators, allowing very precise, fine grained demonstrations on the exact platform where the ultimate imitation learning policy would be deployed.

Mobile ALOHA demonstrates fine manipulation to accomplish realistic kitchen tasks
The Mobile ALOHA authors admit that their setup allowed the robot to learn from nearly optimal, expert human operators. Still, collecting high quality demonstrations directly on the target deployment platform through teleoperation is clearly an approach that will yield compelling results, even if they don’t generalize well. It will be interesting to see how nearly optimal teleoperation data is combined with suboptimal, larger scale data in the future. This may become analogous to the multiple steps of fine-tuning that modern LLMs go through (SFT, RLHF or DPO, etc.) to tailor them to a particular task like responding to user prompts. And, reconnecting the use of language labels, prior work in BC-Z confirms that even policies learning to imitate precise, platform-specific teleoperated demonstrations still generalize better when tasked with reconstructing the language representation in addition to imitating the expert.
While imitation learning from platform-specific expert demonstrations has shown some of the most compelling recent results, there are natural limits to this technique. Requiring that human experts demonstrate the task constrains robot morphologies and naturally bounds robot capabilities by what human demonstrators can do. The long-term promise isn’t just to get robots that can do what humans do, but also robots that can reliably take on tasks that are too challenging or dangerous for humans to do reliably. In this area, behavior cloning falls short. Collecting demonstrations from humans is also very costly, and it isn’t clear yet whether designing lost cost demonstration frameworks (for example, using VR systems) will allow this type of data to be scaled up.
Helping robots learn nuanced human preferences
In addition to demonstrating the power of massive datasets and large transformer models, the LLM training pipeline also contains additional steps that might be successfully adapted to robotics to derive value from robotics data. A key component of the system is the process of learning a reward model based on collected preference data. For LLMs, this means rating two or more responses to an input prompt. This step has proven essential to the performance of modern LLMs and is a key area of LLM innovation (see DPO and similar reformulations of this step). For LLMs, the reward model is used to further fine-tune the target LLM and then discarded. In the robotics context, such a model could prove quite useful not only for fine-tuning robot policies, but also for ongoing evaluation and monitoring of robot systems. Imagine this as a system that can consume an action or trajectory from a robot executing a particular task and provide a simple rating of how “good” the performance was.
Learning from human preferences, published by OpenAI in 2017, actually introduced this idea in the context of training RL agents. The value proposition there is clear and is still extremely relevant for robotics, just as it is for language models: proper execution of a task by an automated system is often simple for humans to judge but challenging for humans to specify. In the case of complex robotic tasks, developing a function to describe the quality of the task execution is extremely tricky and error prone. RL systems are known to exploit any inadequacies in hand-crafted reward functions. By simply asking humans to express their preference, we can model the nuanced criteria that humans implicitly use to judge the quality of the system’s actions.
This may at first glance sound a lot like inverse RL (like GAIL), where an implicit reward function is derived from many demonstrations, but it’s subtly different. In this case, we don’t need humans to provide a demonstration, only a preference label. This simplifies the process considerably and makes it easier to scale. For the robotics domain, there may also be more useful ways to express this reward than just a pairwise preference, like the reward sketching approach proposed by DeepMind in 2020.
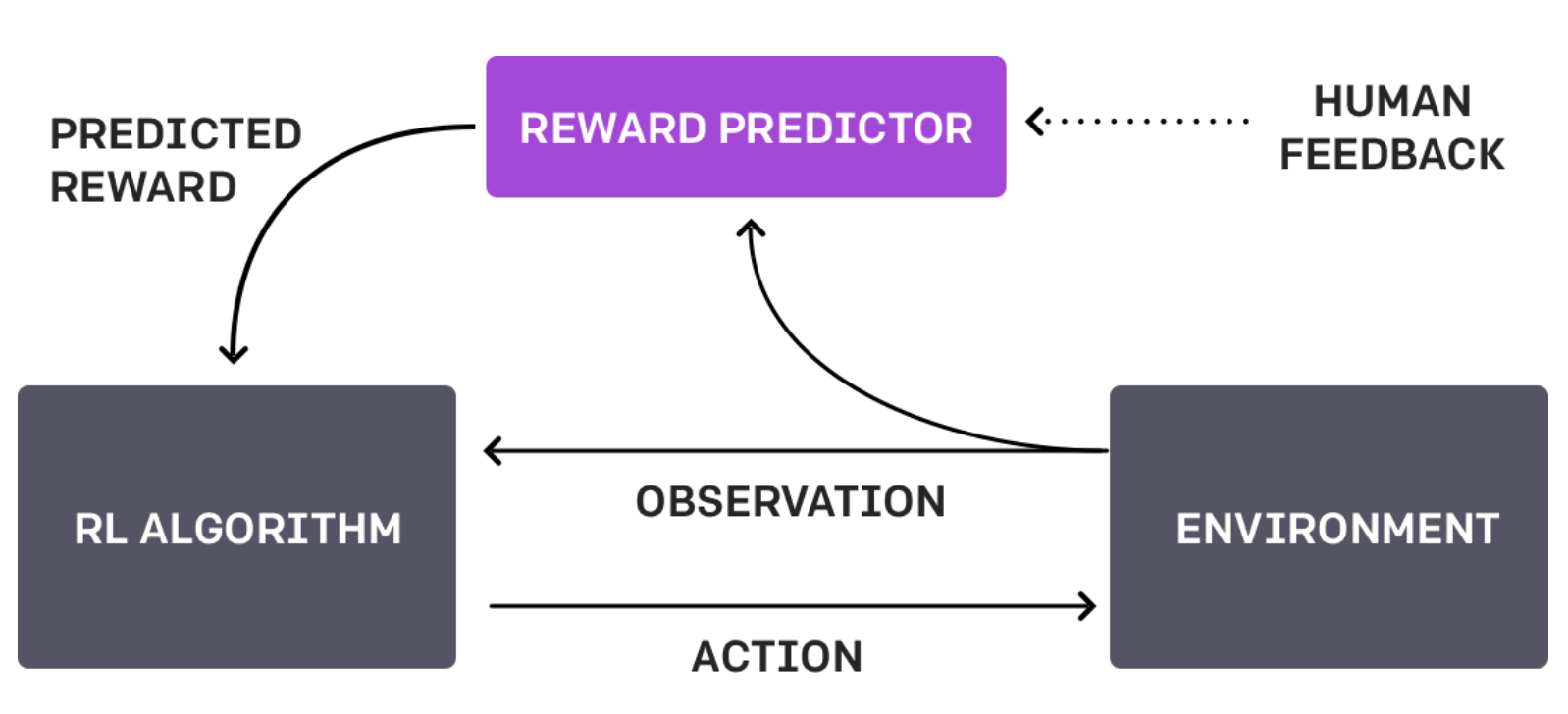
Given how fundamental this step is to achieving state of the art LLM performance, there seems to be surprisingly little research applying this particularly useful LLM process to robotics. The promise seems clear. Given a collection of data from a robotic system and available human review time, capturing pairwise (or ranking) preference labels could help train very powerful reward models for both model training and system evaluation/monitoring.
This approach could also intersect with the discussion above regarding how to represent tasks. One of the challenges with using language to specify the task is ambiguity on how the task should be achieved. A reward predictor over all robot behavior - instead of just task completion - would be extremely useful in encouraging the robot to complete the tasks in a manner consistent with human expectations.
Recent work is already exploring this question. In RoboCLIP, videos of a single task demonstration are processed using a pre-trained encoder (trained on videos of human task completion). Then, sequences of the robot attempting the task are similarly encoded, and the similarity of these encodings is used as the reward signal. With this reward, RL-based fine tuning shows notable success in helping the robot generalize to new tasks with very few demonstrations. The authors note qualitatively that the robot mimics the “style” of the human demonstration. While this formulation is successful for individual tasks, it may not scale well. It does, however, demonstrate a promising approach for using pre-trained encoders for extracting useful reward signals from a very small amount of human demonstrations.
A note on simulation
I have mostly glazed over the topic of simulation in this summary as the use of simulation for enhancing capabilities of manipulation robots is an entire domain of academic research far too extensive to explore here. Work summarized above contains a mix of real world and simulation results, and for purposes of exploring the techniques, I’ve considered results in either domain to be roughly equivalent. This assumption is of course heavily flawed, as seamlessly converting results to/from sim and the real world is still very much an unsolved problem. That being said, results in the past few years have shown this problem to be getting easier, with techniques like privileged teacher/student and domain randomization proving to be quite successful. Sim will undoubtedly play a key role for large-scale exploration and data acquisition and the reader is highly encouraged to explore related recent work on sim2real techniques. Relevant to grasping and manipulation robots, Scaling Up and Distilling Down is a good place to start.
Conclusions
The dramatic success of LLMs and multi-modal foundation models have inspired a new wave of promising robotics research. The key elements that have led to success with LLMs - scaled up transformer architectures, self-supervised pre-training, and massive datasets - have been explored to some degree with some exciting results. This summary is far from an exhaustive look at the relevant research in this category. The volume of research even in this subdomain of robotics is overwhelming, and I would encourage the reader to examine cited papers of interest in each of the works I mention here.
So what does this all mean for someone with a bunch of data from robots in the wild, looking to make use of it? Below are a few key conclusions and ideas.
Language is essential for generalization. The data that best helps with robot generalization (both across robots and across tasks) contains language annotations. The Voltron authors summarize it well: “…language supervision works to enrich visual representations (even in the absence of language downstream), while visual supervision similarly enriches language representations.” The most powerful pre-trained vision encoders all lean on language to aid with generalization and to bridge domains. While task specifications aside from language (like goal-conditioned formulations) have shown some promise, it was very clear in the Octo results that language-conditioned policies remain far superior to goal-conditioned policies. More generally, language is proving to be an undeniably critical component for generalization both in this narrow subdomain of robotics and in numerous other areas in the broader field of AI.
Domain-specific data remains useful. The results are clear that data acquired from robots appears to have higher utility than data acquired from other sources, including ego-centric human videos or more generic data. This conclusion is very tenuous, however, and the sheer scale of videos of humans doing tasks is so enormous that the data volume may ultimately prove to be more useful. Still, at the current state of the research, data generated directly from robots appears to be more useful than task-specific data extracted from other sources. Although being able to learn from videos of expert humans performing tasks would be a dream for scalability, more research is needed to truly take advantage of this data.
Robot-specific data, combined with imitation learning, produces the best single-task performance but is hard to scale. Robot-specific expert demonstration data acquired through teleoperation remains the best way to achieve the highest performance on a single task. Mobile ALOHA and related work shows that expert demonstrations collected directly on the target platform are very powerful. Diffusion Policy reinforces the remarkable effectiveness of a relatively small amount of data (50-100) demonstrations for learning new tasks. The VC-1 authors, while showing impressive generalization of their pretrained representations, still admitted that encoders trained on task-specific data still outperform in some areas. Scaled up, highly diverse datasets are useful if you’re trying to generalize to new tasks, but if you can get data from the target robot for the specific task, that’s still going to produce the best results. However, this approach is limited to robot morphologies and tasks where humans can feasibly provide demonstration examples. Still, the incredible behavior cloning results will be appealing for companies working on dexterous robots and I expect to see teleoperation rigs of various forms (direct, VR, etc.) to become common as a way to enable large-scale acquisition of demonstrate data. 1X even refers to these demonstrators as “android operators.”
LLMs alone do not enable generalized robots. There is some evidence that adapting large, pre-existing LLMs to robotics tasks can be moderately successful, but it’s also clear now after many attempts at this that simply embedding an LLM in a visio-motor robot policy doesn’t magically convert the robot into a fully capable android. Directly leveraging LLMs does reduce the need to collect and tediously annotate massive datasets, particularly for new tasks, and increasingly capable LLMs may contain a superset of the capabilities needed for many robotics tasks. Still, despite various increasingly clever approaches to try to extract LLM reasoning for robot tasks, the reasoning power LLMs displayed in the language domain has not transferred entirely to robotics yet. Of course, the prize here is too alluring, and several teams are finding increasingly clever applications for LLMs in the robot learning pipeline. One approach to keep an eye on is used in Scaling up and Distilling Down, where an LLM is used to specify tasks and completion criteria to guide large-scale exploration by the robot. Eureka is an even more straightforward example where an LLM is used to write and tune reward functions used for training RL agents.
Reward modeling and fine tuning is an area of opportunity. More work should be done to explore whether other lessons from LLMs, like the notable benefits of the rapidly advancing LLM fine-tuning pipeline, could be adapted to robotics. The task and robot-specific fine tuning done in many of the discussed works does directly mirror the SFT step of the LLM tuning pipeline. However, the RLHF/DPO stage of the pipeline does not have a mirrored approach for robotics. If large robotics datasets contain many similar trajectories, annotating human preference labels among these options and learning a useful reward model could prove useful. Such a model might be useful directly for fine tuning, but also for evaluation purposes, runtime monitoring, or other tasks aside from directly improving the robot’s behavior.
Don’t just reach for scale. Despite the triumphs of scale in the language domain, scaling alone may not solve remaining problems and scaling further presents numerous challenges for real-time inference on robot platforms. In general, the models being learned on robotics data or ego-centric video data are relatively quite small. Octo (trained on Open-X dataset) is 93M parameters; most modern LLMs are billions of parameters at minimum. VC-1 was trained with 5.6M images; CLIP was trained with at least 400M. It’s possible that continuing to scale pre-trained encoders on robotics data will have benefits, but it isn’t clear yet if the scaling properties applicable to LLMs will apply to robotics. In fact, we have some evidence they may not. RT-2 showed that scaling the LLM at the heart of the architecture from 5B to 55B parameters did not meaningfully improve performance on unseen tasks (and imposed real challenges for inference, requiring cloud-based GPUs to run the model). If this much larger LLM contained more reasoning than the 5B model, the resulting policy was unable to extract that reasoning for robotics tasks. The VC-1 authors noted that scaling up the size of the encoder improves performance on average, but not universally across tasks, and the authors noted that only modest scaling trends for both model size and dataset diversity.
Appendix
Open X-Embodiment dataset breakdown
Relevant and insightful lectures and talks by some of the researchers/leads involved in this area: